App Engine
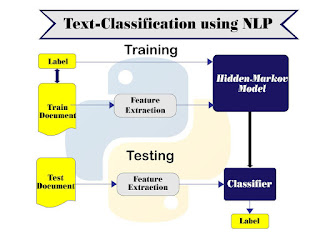
The process of splitting written text into meaningful components, such as words, sentences, or phrases, is known as text segmentation. Natural language processing refers to both the mental processes that humans utilise when reading text and the artificial processes that are implemented in computers. This blog describes how text segmentation can be performed with the help of Hidden Markov model(HMM) Natural language processing (NLP) challenges are where naive Bayes are most commonly utilised. Naive Bayes predicts a text's tag. They calculate each tag's probability for a given text and output the tag with the highest probability. In Naive Bayes, we calculate the probability of label y using the joint probability, assuming that the input values are conditionally independent. Because letter or word sequences are dependent, this assumption does not hold true in the text segmentation problem. We present a parameter-free text segmentation approach b...




